
How AI Learns
Lesson Summary:
Neural networks are the beating heart of modern AI, silently learning patterns from oceans of data. In this lesson you’ll peek behind the curtain—visualizing layers and weights, decoding back-propagation, and comparing silicon synapses to our own gray matter. By the end, abstract math feels tangible, and the next AI headline suddenly makes perfect sense.

Why Machines Imitate Minds
Metaphor: Think of a neural network as a choir. Each layer is a section—sopranos, altos, tenors, basses—passing notes forward until harmony emerges.
Layers: Stacked groups of neurons that transform data step by step.
Weights: Adjustable “volume knobs” on each connection.
Back-propagation: The rehearsal: wrong notes echo backward, telling each singer how to adjust volume next time.
Discover the untold story behind the breakthrough that launched the modern AI era. "When Machine Vision Went Critical" unpacks how AlexNet and ImageNet didn’t just revolutionize computer vision—they redefined what machines could see, and how they see us. This article traces the rise of deep learning from technical triumph to social transformation, exposing the invisible labor, encoded bias, and power asymmetries embedded in today’s smartest systems. For engineers, ethicists, and everyday users alike, it’s a must-read map of where we’ve been, what we’ve built, and why it matters now more than ever.
When a neural network begins training, its weights are initialized randomly - typically small values drawn from a normal distribution around zero. At this stage, the network has no knowledge about which inputs are important for the task at hand. Every connection between neurons starts with arbitrary strength.
Think of it like a new employee who doesn't yet know which aspects of their job are most critical. They treat everything equally because they lack experience.
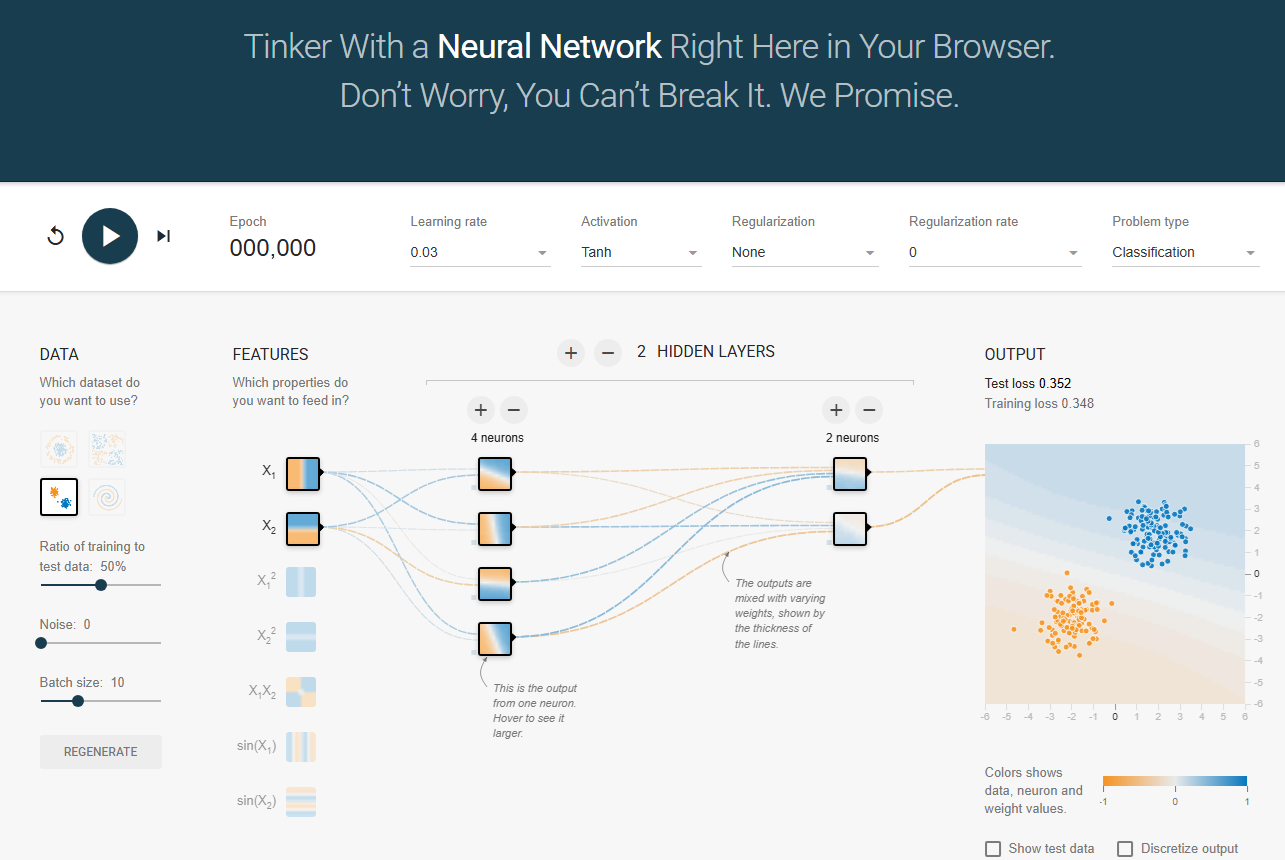
A Concrete Example
Imagine training a network to recognize handwritten digits. Initially, all pixel positions have random, roughly equal importance. But through learning:
Pixels in the center of the image develop larger weights (more important for distinguishing digits)
Edge pixels might develop smaller weights (less informative)
Specific patterns emerge: curved edges become important for recognizing 0s, 6s, 8s, 9s
Straight vertical lines become important for 1s and 7s
The network essentially learns a hierarchy of feature importance - which parts of the input space contain the most predictive information for the task.
This weight adjustment process is what allows neural networks to automatically discover which aspects of complex, high-dimensional inputs actually matter for making accurate predictions. The beauty is that this importance ranking emerges naturally from the data, rather than being hand-coded by humans.
“The brain is just a machine—and so is a neural network. The trick is getting the machine to dream.”
-
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436–444. Publisher link
Ng, A. (2020). Machine Learning Specialization [MOOC]. DeepLearning.AI & Stanford Online. Available on Coursera